
Self-Attention Kernels: High-Performance Computing
This project implements Causal Multi-Head Self-Attention (CMHSA) with three optimized backends, designed for high-performance deep learning inference:
- Single-threaded CPU - Baseline implementation with SIMD optimizations
- Multi-threaded CPU - OpenMP parallelization with tiled memory access patterns
- CUDA GPU - Hand-optimized kernels achieving 1.09x speedup vs PyTorch naive on A100 GPUs
Performance Highlights
Benchmarks on Cineca (A100 GPUs) and Orfeo HPC clusters demonstrate significant speedups through iterative optimization:
- CUDA v4.6: 1.09× faster than PyTorch naive baseline on A100
- Strong Scaling: Near-linear scaling up to 128 threads on CPU
- Multi-threaded: 8.11× speedup vs single-thread on 128 cores
Technical Stack
- Languages: CUDA, C++, C, Python
- Libraries: OpenMP, PyTorch (for validation)
- Hardware: NVIDIA A100 GPUs, x86_64 multi-core CPUs
- Testing: Validated against GPT-2 attention layer outputs
This work bridges the gap between deep learning algorithms and systems-level optimization, demonstrating expertise in both ML theory and high-performance computing.
🔗 GitHub Repository: Self_Attention_Kernels
📊 Performance Charts: See repository for detailed benchmarks on Cineca A100 and Orfeo clusters
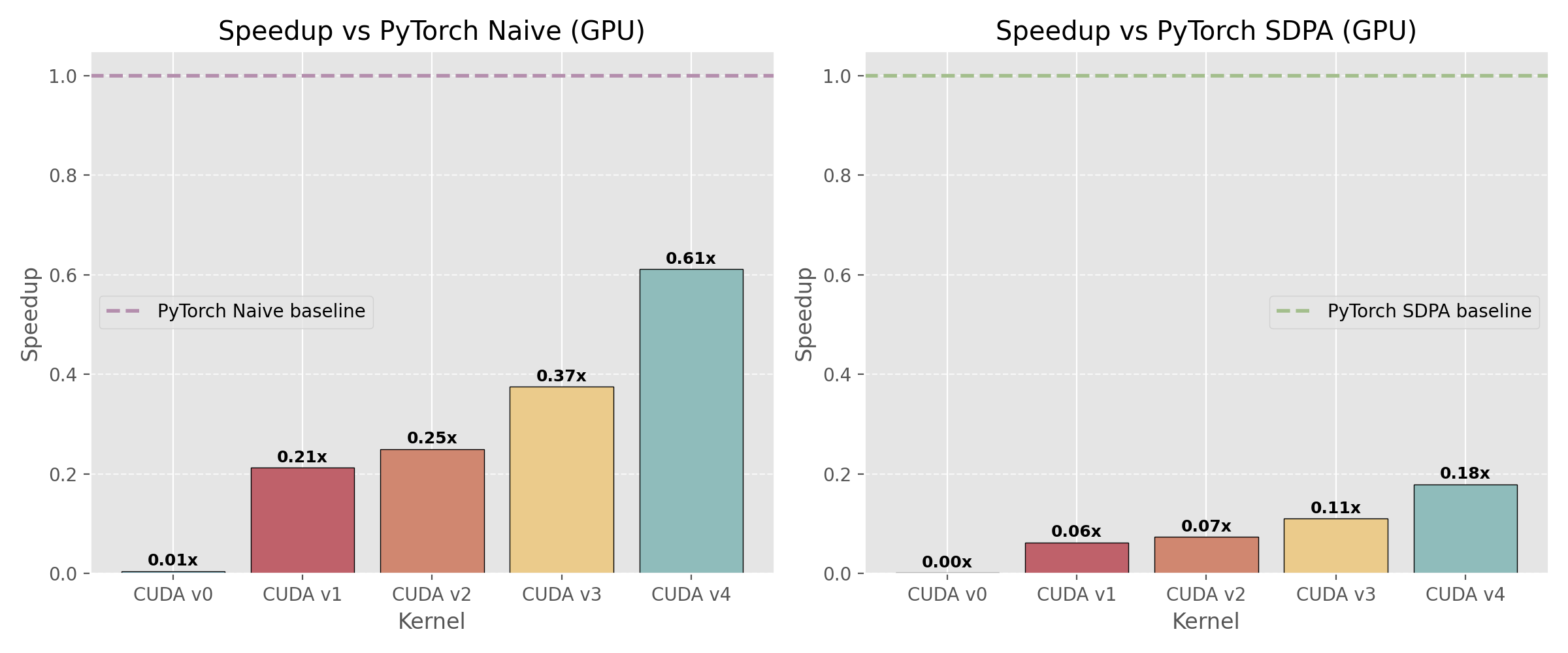
CUDA kernel performance comparison on Orfeo cluster showing progressive optimization from v3 to v6
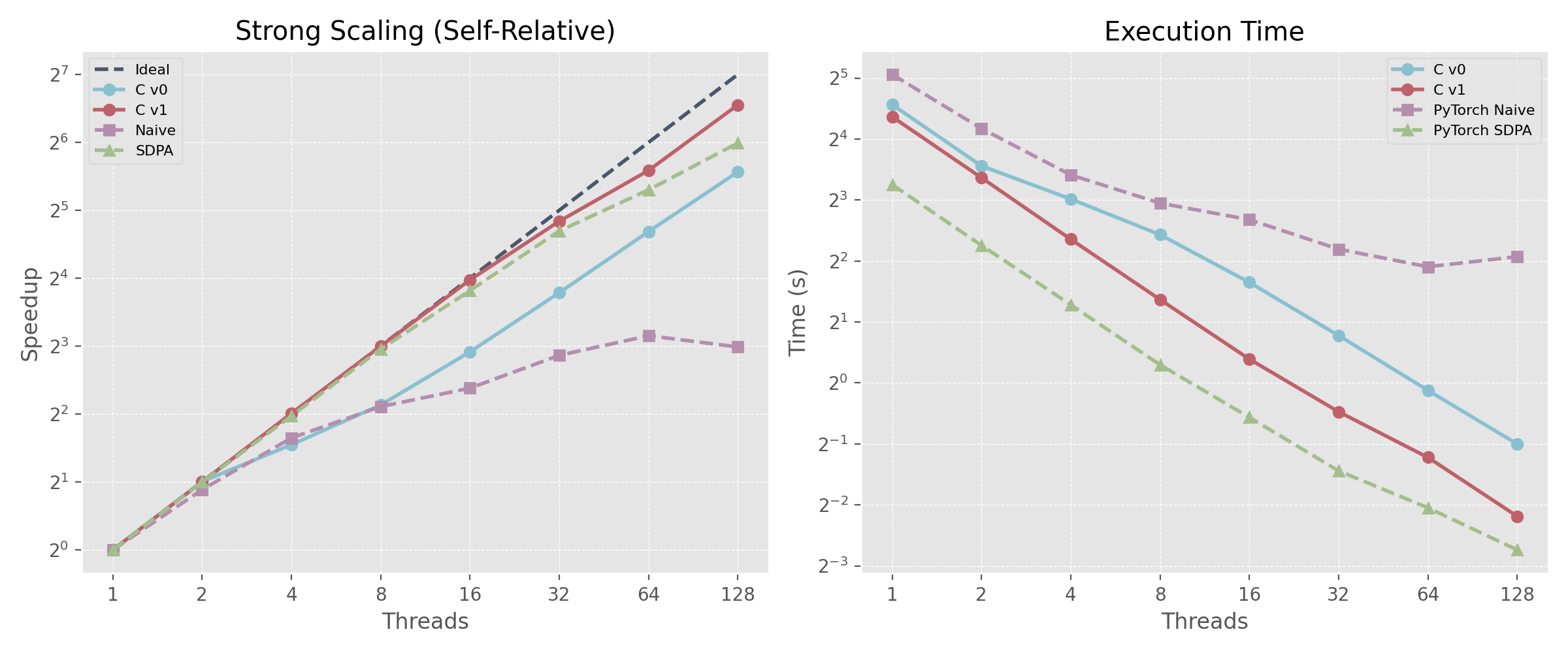
Strong scaling results demonstrating near-linear speedup across 1-128 threads